- Регистрация
- 23 Август 2023
- Сообщения
- 3 163
- Лучшие ответы
- 0
- Реакции
- 0
- Баллы
- 51
Offline
And why the path to real intelligence goes through ontologies and knowledge graphs
Those who follow me, might remember a similar AI rant from a year ago, under the pseudonym “Grumpy Risk Manager”. Now I’m back, grumpier than ever, with specific examples but also ideas for solutions!

Source: author collage
Introduction
LLMs are at the peak of their hype. They are considered “intelligent” due to their ability to answer and discuss generic topics in natural language.
However, once you dive into a specialist/complex domains such as medicine, finance, law, it is easy to observe logical inconsistencies, plain mistakes and the so called “hallucinations”. To put it simply, the LLM behaves like a pupil with a very rich dictionary who tries to pretend that they’ve studied for the exam and know all the answers, but they actually don’t! They just pretend to be intelligent due to the vast information at their disposal, but their ability to reason using this information is very limited. I would even go a step further and say that:
Let me give you a real example from the domain in which I’ve spent the last 10 years — financial risk. Good evidence of it being “specialist” is the amount of contextual information that has to be provided to the average person in order to understand the topic:
The topic in the 9 statements above seems complex and it really is, there are dozens of additional complications and cases that exist, but which I’ve avoided on purpose, as they are not even necessary for illustrating the struggle of AII with such topics. Furthermore, the complexity doesn’t arise from any of the individual 9 rules itself, but rather from their combination, there are a lot of concepts whose definition is based on several other concepts giving rise to a semantic net/graph of relationships connecting the concepts and the rules.
Now let’s focus only on the core concepts and rules in 4, which can be summarised as follows: rating → CQS → risk-weight → capital requirement. If we also look at an example CRR article 122, we can see a mapping table CQS → risk-weight which should be used for corporate exposures.
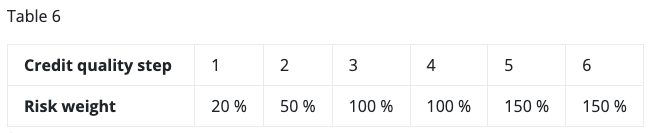
Capital Requirements Regulation (CRR 122)
This mapping rule is very simple, it can be understood easily by the average person with a bit of context. It is also known by many banking specialists and most of them don’t memorise the exact rule but simply know the information of the 9 statements above and know where to look in order to see the exact mapping.
Artificially Imitated Intelligence
Now let’s formulate a question and see whether AII can deal with it, here is what I asked ChatGPT 3.5:
And here is the answer:
Can you spot the factual mistakes, highlighted in bold?
Enter ontologies, a form of knowledge representation of a particular domain. One good way of thinking about it, is in terms of ordering the different ways of representing knowledge from least to more sophisticated:
Why would one want to incorporate such complex relational structure in their data? Below are the benefits which will be later illustrated with an example:
Ontologies can be considered one of the earliest and purest forms of AI, long before large ML models became a thing and all based on the idea of making data smart via structuring. Here by AI, I mean real intelligence — the reason the ontology can explain the evaluated result of a given rule is because it has semantic understanding about how things work! The concept became popular first under the idea of Semantic Web in the early 2000s, representing the evolution of the internet of linked data (Web 3.0), from the internet of linked apps (Web 2.0) and the internet of linked pages (Web 1.0).
Knowledge Graphs (KGs) are a bit more generic term for the storage of data in graph format, which may not necessarily follow ontological and semantic principles, while the latter are usually represented in the form of a KG. Nowadays, with the rise of LLMs, KGs are often seen as a good candidate for resolving their weaknesses in specialist domains, which in turn revives the concept of ontologies and their KG representation.
This leads to very interesting convergence of paradigms:
Now imagine a perfect world in which regulations such as the CRR are provided in the form of ontology rather than free text.
The below example aims to illustrate these ideas on a minimal effort, maximum impact basis!
Example
On the search for solutions of the illustrated LLM weaknesses, I designed the following example:
For creating the simple ontology, I used the CogniPy library with the main benefits of:
First, let’s start by defining the structure of our ontology. This is similar to defining classes in objective oriented programming with different properties and constraints.
In the first CNL statement, we define the company class and its properties.
Every company has-id one (some integer value) and has-cqs one (some integer value) and has-turnover (some double value).
Several things to note is that class names are with small letter (company). Different relationships and properties are defined with dash-case, while data types are defined in the brackets. Gradually, this starts to look more and more like a fully fledged programming language based on plain English.
Next, we illustrate another ability to denote the uniqueness of the company based on its id via generic class statement.
Every X that is a company is-unique-if X has-id equal-to something.
Data
Now let’s add some data or instances of the company class, with instances starting with capital letter.
Lamersoft is a company and has-id equal-to 123 and has-cqs equal-to 5 and has-turnover equal-to 51000000.
Here we add a data point with a specific company called Lamersoft, with assigned values to its properties. Of course, we are not limited to a single data point, we could have thousands or millions in the same ontology and they can be imported with or without the structure or the logic components.
Now that we’ve added data to our structure, we can query the ontology for the first time to get all companies, which returns a DataFrame of instances matching the query:
onto.select_instances_of("a thing that is a company")

DataFrame with query results
We can also plot our knowledge graph, which shows the relationship between the Lamersoft instance and the general class company:
onto.draw_graph(layout='hierarchical')
Ontology graph
Logic
Finally, let’s add some simple rules implementing the CRR risk-weight regulations for corporates.
If a company has-turnover greater-than 50000000 then the company is a corporate.
If a corporate has-cqs equal-to 5 then the corporate has-risk-weight equal-to 1.50.
The first rule defines what a corporate is, which usually is a company with large turnover above 50 million. The second rule implements part of the CRR mapping table CQS → risk-weight which was so hard to understand by the LLM.
After adding the rules, we’ve completed our ontology and can plot the knowledge graph again:
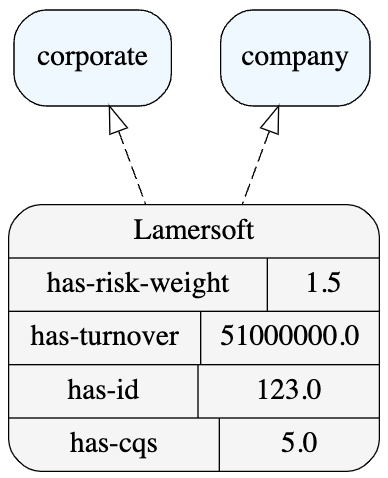
Ontology graph with evaluated rules
Notably, 2 important deductions have been made automatically by the knowledge graph as soon as we’ve added the logic to the structure and data:
This is all as a result of the magical automated consistency (no conflicts) of all information in the ontology. If we were to add any rule or instance that contradicts any of the existing information we would get an error from the reasoner and the knowledge graph would not be materialised.
Now we can also play with the reasoner and ask why a given evaluation has been made or what is the chain of thought and audit trail leading to it:
printWhy(onto,"Lamersoft is a corporate?")
{
"by": [
{
"expr": "Lamersoft is a company."
},
{
"expr": "Lamersoft has-turnover equal-to 51000000."
}
],
"concluded": "Lamersoft is a corporate.",
"rule": "If a company has-turnover greater-than 50000000 then the company is a corporate."
}
Regardless of the output formatting, we can still clearly read that by the two expressions defining Lamersoft as a company and its specific turnover, it was concluded that it is a corporate because of the specific turnover condition. Unfortunately, the current library implementation doesn’t seem to support an explanation of the risk-weight result, which is food for the future ideas section.
Nevertheless, I deem the example successful as it managed to unite in a single scalable ontology, structure, data and logic, with minimal effort and resources, using natural English. Moreover, it was able to make evaluations of the rules and explain them with a complete audit trail.
One could say here, ok what have we achieved, it is just another programming language closer to natural English, and one could do the same things with Python classes, instances and assertions. And this is true, to the extent that any programming language is a communication protocol between human and machine. Also, we can clearly observe the trend of the programming syntaxes moving closer to the human language, from the Domain Driven Design (DDD) focusing on implementing the actual business concepts and interactions, to the LLM add-ons of Integrated Development Environments (IDEs) to generate code from natural language. This becomes a clear trend:
Imagine a world in which all banking regulations are provided centrally by the regulator not in the form of text but in the form of an ontology or smart data, that includes all structure and logic. While individual banks import the central ontology and extend it with their own data, thus automatically evaluating all rules and requirements. This will remove any room for subjectivity and interpretation and ensure a complete audit trail of the results.
Beyond regulations, enterprises can develop their own ontologies in which they encode, automate and reuse the knowledge of their specialists or different calculation methodologies and governance processes. On an enterprise level, such ontology can add value for enforcing a common dictionary and understanding of the rules and reduce effort wasted on interpretations and disagreements which can be redirected to building more knowledge in the form of ontology. The same concept can be applied to any specialist area in which:
Then we can call intelligence our ability to accumulate knowledge and to query it for getting actionable insights. This can evolve into specialist AIs that tap into ontologies in order to gain expertise in a given field and reduce hallucinations.
LLMs are already making an impact on company profits — Klarna is expected to have $40 million improvement on profits as a result of ChatGPT handling most of its customer service chats, reducing the costs for human agents.
Note however the exact area of application of the LLM! This is not the more specialised fields of financial/product planning or asset and liabilities management of a financial company such as Klarna. It is the general customer support service, which is the entry level position in many companies, which already uses a lot of standardised responses or procedures. The area in which it is easiest to apply AI but also in which the value added might not be the largest. In addition, the risk of LLM hallucination due to lack of real intelligence is still there. Especially in the financial services sector, any form of “financial advice” by the LLM can lead to legal and regulatory repercussions.
Future ideas
LLMs already utilise knowledge graphs in the so-called Retrieval-Augmented Generation (RAG). However, these graphs are generic concepts that might include any data structure and do not necessarily represent ontologies, which use by LLMs is relatively less explored. This gives me the following ideas for next article:
A proof of concept that achieves all 3 points above can claim the title of true AI, it should be able to develop knowledge in a smart data structure which is both human and machine readable, and query it via natural language to get actionable insights with complete transparency and audit trail.
Follow me for part 2!

The struggle of Artificially Imitated Intelligence in specialist domains was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Those who follow me, might remember a similar AI rant from a year ago, under the pseudonym “Grumpy Risk Manager”. Now I’m back, grumpier than ever, with specific examples but also ideas for solutions!
Source: author collage
Introduction
- Large Language Models (LLMs) like ChatGPT are impressive in their ability to discuss generic topics in natural language.
- However, they struggle in specialist domains such as medicine, finance and law.
- This is due to lack of real understanding and focus on imitation rather than intelligence.
LLMs are at the peak of their hype. They are considered “intelligent” due to their ability to answer and discuss generic topics in natural language.
However, once you dive into a specialist/complex domains such as medicine, finance, law, it is easy to observe logical inconsistencies, plain mistakes and the so called “hallucinations”. To put it simply, the LLM behaves like a pupil with a very rich dictionary who tries to pretend that they’ve studied for the exam and know all the answers, but they actually don’t! They just pretend to be intelligent due to the vast information at their disposal, but their ability to reason using this information is very limited. I would even go a step further and say that:
The so-called Artificial Intelligence (AI) is very often Artificial Imitation of Intelligence (AII). This is particularly bad in specialist domains like medicine or finance, since a mistake there can lead to human harm and financial losses.
Let me give you a real example from the domain in which I’ve spent the last 10 years — financial risk. Good evidence of it being “specialist” is the amount of contextual information that has to be provided to the average person in order to understand the topic:
- Banks are subject to regulatory Capital requirements.
- Capital can be considered a buffer which absorbs financial losses.
- The requirements to hold Capital, ensures that banks have sufficient capability to absorb losses reducing the likelihood of bankruptcy and financial crisis.
- The rules for setting the requirements in 1. are based on risk-proportionality principles:
→ the riskier the business that banks undertake
→ higher risk-weights
→ higher capital requirements
→ larger loss buffer
→ stable bank - The degree of riskiness in 4. is often measured in the form of credit rating of the firms with which the bank does business.
- Credit ratings come from different agencies and in different formats.
- In order to standardise the ratings, regulators have created mapping rules from every rating format to the standardised Credit Quality Step (CQS) in the range of 1 to 6.
- Then the regulatory rules for determining the risk-weights in 4. are based on the CQS.
- The rules in 8. for European banks are set in the Capital Requirements Regulation (CRR).
The topic in the 9 statements above seems complex and it really is, there are dozens of additional complications and cases that exist, but which I’ve avoided on purpose, as they are not even necessary for illustrating the struggle of AII with such topics. Furthermore, the complexity doesn’t arise from any of the individual 9 rules itself, but rather from their combination, there are a lot of concepts whose definition is based on several other concepts giving rise to a semantic net/graph of relationships connecting the concepts and the rules.
Now let’s focus only on the core concepts and rules in 4, which can be summarised as follows: rating → CQS → risk-weight → capital requirement. If we also look at an example CRR article 122, we can see a mapping table CQS → risk-weight which should be used for corporate exposures.
Capital Requirements Regulation (CRR 122)
This mapping rule is very simple, it can be understood easily by the average person with a bit of context. It is also known by many banking specialists and most of them don’t memorise the exact rule but simply know the information of the 9 statements above and know where to look in order to see the exact mapping.
Artificially Imitated Intelligence
Now let’s formulate a question and see whether AII can deal with it, here is what I asked ChatGPT 3.5:
According to CRR, what is the risk-weight of an exposure to corporate which has credit quality step of 5?
And here is the answer:
In the Capital Requirements Regulation (CRR), the risk-weight of an exposure to a corporate entity depends on its credit quality step. In the context of credit quality steps, a credit quality step of 5 typically represents the highest credit quality, indicating a very low risk of default.
In the standardised approach outlined in the CRR, exposures to corporates are assigned risk weights based on their credit ratings or credit quality steps. The risk weights for exposures to corporates range from 20% to 150%, depending on the credit quality step and whether the exposure is short-term or long-term.
Since a credit quality step of 5 signifies a very low risk, the corresponding risk weight assigned to such an exposure would be one of the lowest. In this case, for a corporate with a credit quality step of 5, the risk weight would likely be 20% or similar, indicating a low capital requirement for banks holding such exposures.
Can you spot the factual mistakes, highlighted in bold?
- First very big mistake is that the AII completely misunderstood and inverted the CQS → risk-weight relationship, high CQS of 5 doesn’t represent low risk but exactly the opposite, it is one of the highest risks! This is actually the biggest mistake one could possibly make when answering this question!
- Even after the mistake in 1, I would expect the AII to be able to look-up a table in an article and conclude that below a CQS of 5, there is a risk-weight of 150%. But no, the AII confidently claims 20% risk-weight, due to low risk…
- Although undeserved, I still gave the benefit of doubt to the AII, by asking the same question but clarifying the exact CRR article: 122. Shameless, but confident, the AII now responded that the risk-weight should be 100%, still claiming that CQS of 5 is good credit quality → another obvious mistake.
Feeling safe for my job and that the financial industry still needs me, I started thinking about solutions, which ironically could make my job unsafe in the future…
Why ontologies and knowledge graphs?Enter ontologies, a form of knowledge representation of a particular domain. One good way of thinking about it, is in terms of ordering the different ways of representing knowledge from least to more sophisticated:
- Data dictionary: table with field names and metadata attributes
- Taxonomy: table/s with added nesting of data types and sub-types in terms of relationships (e.g. Pigeon <is a type of> Bird)
- Ontology: Multidimensional taxonomies with more than one type of relationships (e.g. Birds <eat> Seeds) “the unholy marriage of a taxonomy with object oriented programming” (Kurt Cagle, 2017)
Why would one want to incorporate such complex relational structure in their data? Below are the benefits which will be later illustrated with an example:
- Uniform representation of: structure, data and logic. In the example above, Bird is a class which is a template with generic properties = structure. In an ontology, we can also define many actual instances of individual Birds with their own properties = data. Finally, we can also add logic (e.g. If a Bird <eats> more than 5 Seeds, then <it is> not Hungry). This is essentially making the data “smart” by incorporating some of the logic as data itself, thus making it a reusable knowledge. It also makes information both human and machine readable which is particularly useful in ML.
- Explainability and Lineage: most frequent implementation of ontology is via Resource Description Framework (RDF) in the form of graphs. These graphs can then be queried in order to evaluate existing rules and instances or add new ones. Moreover, the chain of thought, through the graph nodes and edges can be traced, explaining the query results and avoiding the ML black box problem.
- Reasoning and Inference: when new information is added, a semantic reasoner can evaluate the consequences on the graph. Moreover, new knowledge can be derived from existing one via “What if” questions.
- Consistency: any conflicting rules or instances that deviate from the generic class properties are automatically identified as an error by the reasoner and cannot become part of the graph. This is extremely valuable as it enforces agreement of knowledge in a given area, eliminating any subjective interpretations.
- Interoperability and Scalability: the reusable knowledge can focus on a particular specialist domain or connect different domains (see FIBO in finance, OntoMathPRO in maths, OGMS in medicine). Moreover, one could download a general industry ontology and extend it with private enterprise data in the form of instances and custom rules.
Ontologies can be considered one of the earliest and purest forms of AI, long before large ML models became a thing and all based on the idea of making data smart via structuring. Here by AI, I mean real intelligence — the reason the ontology can explain the evaluated result of a given rule is because it has semantic understanding about how things work! The concept became popular first under the idea of Semantic Web in the early 2000s, representing the evolution of the internet of linked data (Web 3.0), from the internet of linked apps (Web 2.0) and the internet of linked pages (Web 1.0).
Knowledge Graphs (KGs) are a bit more generic term for the storage of data in graph format, which may not necessarily follow ontological and semantic principles, while the latter are usually represented in the form of a KG. Nowadays, with the rise of LLMs, KGs are often seen as a good candidate for resolving their weaknesses in specialist domains, which in turn revives the concept of ontologies and their KG representation.
This leads to very interesting convergence of paradigms:
- Ontologies aim to generate intelligence through making the data smart via structure.
- LLMs aim to generate intelligence through leaving the data unstructured but making the model very large and structural: ChatGPT has around 175 billion parameters!
Clearly the goal is the same, and the outcome of whether the data becomes part of the model or the model becomes part of the data becomes simply a matter of reference frame, inevitably leading to a form of information singularity.
Why use ontologies in banking?- Specialisation: as shown above, LLMs struggle in specialist fields such as finance. This is particularly bad in a field in which mistakes are costly. In addition, value added from automating knowledge in specialist domains that have fewer qualified experts can be much higher than that of automation in generic domains (e.g. replacing banking expert vs support agent).
- Audit trail: when financial items are evaluated and aggregated in a financial statement, regulators and auditors expect to have continuous audit trail from all granular inputs and rules to the final aggregate result.
- Explainability: professionals rely on having a good understanding of the mechanisms under which a bank operates and impact of risk drivers on its portfolios and business decisions. Moreover, regulators explicitly require such understanding via regular “What if” exercises in the form of stress testing. This is one of the reasons ML has seen poor adoption in core banking — the so-called black box problem.
- Objectivity and Standardisation: lack of interpretation and subjectivity ensures level playing field in the industry, fair competition and effectiveness of the regulations in terms of ensuring financial stability.
Now imagine a perfect world in which regulations such as the CRR are provided in the form of ontology rather than free text.
- Each bank can import the ontology standard and extend it with its own private data and portfolio characteristics, and evaluate all regulatory rules.
- Furthermore, the individual enterprise strategy can be also combined with the regulatory constraints in order to enable automated financial planning and optimised decision making.
- Finally, the complex composite impacts of the big graph of rules and data can be disentangled in order to explain the final results and give insights into previously non-obvious relationships.
The below example aims to illustrate these ideas on a minimal effort, maximum impact basis!
Example
On the search for solutions of the illustrated LLM weaknesses, I designed the following example:
- Create an ontology in the form of a knowledge graph.
- Define the structure of entities, add individual instances/data and logic governing their interactions, following the CRR regulation.
- Use the knowledge graph to evaluate the risk-weight.
- Ask the KG to explain how it reached this result.
For creating the simple ontology, I used the CogniPy library with the main benefits of:
- Using Controlled Natural Language (CNL) for both writing and querying the ontology, meaning no need to know specific graph query languages.
- Visualisation of the materialised knowledge graphs.
- Reasoners with ability to explain results.
First, let’s start by defining the structure of our ontology. This is similar to defining classes in objective oriented programming with different properties and constraints.
In the first CNL statement, we define the company class and its properties.
Every company has-id one (some integer value) and has-cqs one (some integer value) and has-turnover (some double value).
Several things to note is that class names are with small letter (company). Different relationships and properties are defined with dash-case, while data types are defined in the brackets. Gradually, this starts to look more and more like a fully fledged programming language based on plain English.
Next, we illustrate another ability to denote the uniqueness of the company based on its id via generic class statement.
Every X that is a company is-unique-if X has-id equal-to something.
Data
Now let’s add some data or instances of the company class, with instances starting with capital letter.
Lamersoft is a company and has-id equal-to 123 and has-cqs equal-to 5 and has-turnover equal-to 51000000.
Here we add a data point with a specific company called Lamersoft, with assigned values to its properties. Of course, we are not limited to a single data point, we could have thousands or millions in the same ontology and they can be imported with or without the structure or the logic components.
Now that we’ve added data to our structure, we can query the ontology for the first time to get all companies, which returns a DataFrame of instances matching the query:
onto.select_instances_of("a thing that is a company")
DataFrame with query results
We can also plot our knowledge graph, which shows the relationship between the Lamersoft instance and the general class company:
onto.draw_graph(layout='hierarchical')
Ontology graph
Logic
Finally, let’s add some simple rules implementing the CRR risk-weight regulations for corporates.
If a company has-turnover greater-than 50000000 then the company is a corporate.
If a corporate has-cqs equal-to 5 then the corporate has-risk-weight equal-to 1.50.
The first rule defines what a corporate is, which usually is a company with large turnover above 50 million. The second rule implements part of the CRR mapping table CQS → risk-weight which was so hard to understand by the LLM.
After adding the rules, we’ve completed our ontology and can plot the knowledge graph again:
Ontology graph with evaluated rules
Notably, 2 important deductions have been made automatically by the knowledge graph as soon as we’ve added the logic to the structure and data:
- Lamersoft has been identified as a corporate due to its turnover property and the corporate classification rule.
- Lamersoft’s risk-weight has been evaluated due to its CQS property and the CRR rule.
This is all as a result of the magical automated consistency (no conflicts) of all information in the ontology. If we were to add any rule or instance that contradicts any of the existing information we would get an error from the reasoner and the knowledge graph would not be materialised.
Now we can also play with the reasoner and ask why a given evaluation has been made or what is the chain of thought and audit trail leading to it:
printWhy(onto,"Lamersoft is a corporate?")
{
"by": [
{
"expr": "Lamersoft is a company."
},
{
"expr": "Lamersoft has-turnover equal-to 51000000."
}
],
"concluded": "Lamersoft is a corporate.",
"rule": "If a company has-turnover greater-than 50000000 then the company is a corporate."
}
Regardless of the output formatting, we can still clearly read that by the two expressions defining Lamersoft as a company and its specific turnover, it was concluded that it is a corporate because of the specific turnover condition. Unfortunately, the current library implementation doesn’t seem to support an explanation of the risk-weight result, which is food for the future ideas section.
Nevertheless, I deem the example successful as it managed to unite in a single scalable ontology, structure, data and logic, with minimal effort and resources, using natural English. Moreover, it was able to make evaluations of the rules and explain them with a complete audit trail.
One could say here, ok what have we achieved, it is just another programming language closer to natural English, and one could do the same things with Python classes, instances and assertions. And this is true, to the extent that any programming language is a communication protocol between human and machine. Also, we can clearly observe the trend of the programming syntaxes moving closer to the human language, from the Domain Driven Design (DDD) focusing on implementing the actual business concepts and interactions, to the LLM add-ons of Integrated Development Environments (IDEs) to generate code from natural language. This becomes a clear trend:
The role of programmers as intermediators between the business and the technology is changing. Do we need code and business documentation, if the former can be generated directly from the natural language specification of the business problem, and the latter can be generated in the form of natural language definition of the logic by the explainer?
ConclusionImagine a world in which all banking regulations are provided centrally by the regulator not in the form of text but in the form of an ontology or smart data, that includes all structure and logic. While individual banks import the central ontology and extend it with their own data, thus automatically evaluating all rules and requirements. This will remove any room for subjectivity and interpretation and ensure a complete audit trail of the results.
Beyond regulations, enterprises can develop their own ontologies in which they encode, automate and reuse the knowledge of their specialists or different calculation methodologies and governance processes. On an enterprise level, such ontology can add value for enforcing a common dictionary and understanding of the rules and reduce effort wasted on interpretations and disagreements which can be redirected to building more knowledge in the form of ontology. The same concept can be applied to any specialist area in which:
- Text association is not sufficient and LLMs struggle.
- Big data for effective ML training is not available.
- Highly-qualified specialists can be assisted by real artificial intelligence, reducing costs and risks of mistakes.
If data is nowadays deemed as valuable as gold, I believe that the real diamond is structured data, that we can call knowledge. Such knowledge in the form of ontologies and knowledge graphs can also be traded between companies just like data is traded now for marketing purposes. Who knows, maybe this will evolve into a pay-per-node business model, where expertise in the form of smart data can be sold as a product or service.
Then we can call intelligence our ability to accumulate knowledge and to query it for getting actionable insights. This can evolve into specialist AIs that tap into ontologies in order to gain expertise in a given field and reduce hallucinations.
LLMs are already making an impact on company profits — Klarna is expected to have $40 million improvement on profits as a result of ChatGPT handling most of its customer service chats, reducing the costs for human agents.
Note however the exact area of application of the LLM! This is not the more specialised fields of financial/product planning or asset and liabilities management of a financial company such as Klarna. It is the general customer support service, which is the entry level position in many companies, which already uses a lot of standardised responses or procedures. The area in which it is easiest to apply AI but also in which the value added might not be the largest. In addition, the risk of LLM hallucination due to lack of real intelligence is still there. Especially in the financial services sector, any form of “financial advice” by the LLM can lead to legal and regulatory repercussions.
Future ideas
LLMs already utilise knowledge graphs in the so-called Retrieval-Augmented Generation (RAG). However, these graphs are generic concepts that might include any data structure and do not necessarily represent ontologies, which use by LLMs is relatively less explored. This gives me the following ideas for next article:
- Use plain English to query the ontology, avoiding reliance on particular CNL syntax — this can be done via NLP model that generates queries to the knowledge graph in which the ontology is stored — chatting with KGs.
- Use a more robust way of generating the ontology — the CogniPy library was useful for quick illustration, however, for extended use a more proven framework for ontology-oriented programming should be used like Owlready2.
- Point 1. enables the general user to get information from the ontology without knowing any programming, however, point 2 implies that a software developer is needed for defining and writing to the ontology (which has its pros and cons). However, if we want to close the AI loop, then specialists should be able to define ontologies using natural language and without the need for developers. This will be harder to do, but similar examples already exist: LLM with KG interface, entity resolution.
A proof of concept that achieves all 3 points above can claim the title of true AI, it should be able to develop knowledge in a smart data structure which is both human and machine readable, and query it via natural language to get actionable insights with complete transparency and audit trail.
Follow me for part 2!
The struggle of Artificially Imitated Intelligence in specialist domains was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.